研究トピック Research Topics
LLMの推論能力を向上させるための、論理推論コーパスの自動生成
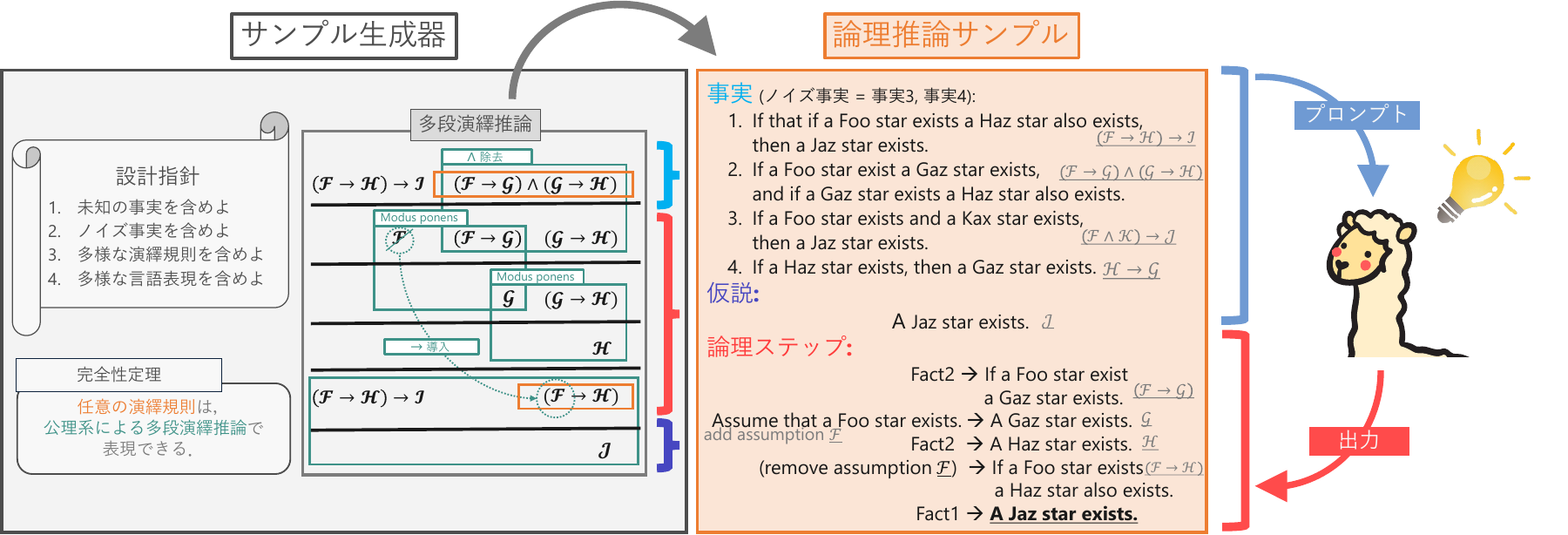
記号論理学に基づく、論理推論サンプルの設計指針を提案。サンプルの自動生成アルゴリズムを開発。大量のサンプルの学習によりLLMの推論能力を大幅に向上。
論理を辿って一歩ずつ考える能力は、人類の知的活動を支える基盤です。 LLMは膨大な知識をもとに自然な文章を生成できますが、それは本当に「論理的に正しい」推論なのでしょうか。
私は、LLMに論理推論を教えるための研究を行っています。
その出発点としてまず、記号論理学の知見などを活用しつつ、論理推論の特徴を整理しました。
論理推論では、例えば「Aという事実と、AならばBという事実から、Bという事実を導く」というような推論規則に従って、新しい事実を導きます。
このような推論規則には多様な種類がありますが、それらは少数の「基礎的な」規則を出発点として導くことができます。
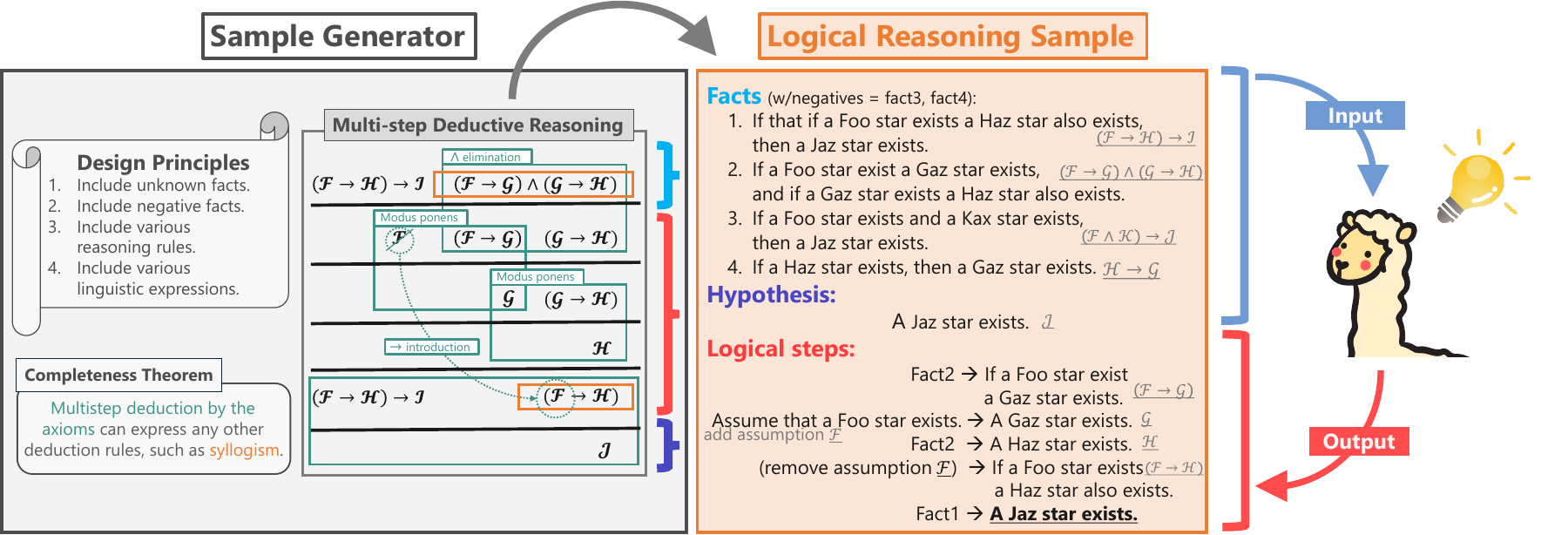
この考えに基づき、私はLLMが論理推論を学ぶための「論理推論問題」を設計しました。 与えられた事実に対して、基礎的な推論規則を一歩ずつ適用し、最終的な答えに到達します。 AやBに対して様々な事実を当てはめた問題により、推論規則の一般性も学べます。 さらに、こうした問題を大量に作成するための自動生成アルゴリズムを開発しました。 推論規則を多段階に積み重ねて問題の骨格を作り、語彙や自然言語テンプレートによって具体的な事実を生成します。
生成した問題を用いてLLMを学習させたところ、論理推論タスクの性能が大きく向上しました。 加えて、数学・科学・コーディングなど、幅広い推論タスクでも性能向上が確認されました。 これは、論理推論がさまざまな推論能力の基礎にあるためだと考えています。
本研究は2022年頃から現在まで継続しています。 学習データだけでなく、LLMの論理推論能力を評価するためのベンチマークも開発しています。 「それらしい答え」ではなく、真に論理的に正しい推論を目指して、研究を進めていきます。
既存発表
-
2026
Can We Teach Logical Reasoning to LLMs? – An Approach Using Synthetic Corpora link
AAAI Bridge Program "Logical and Symbolic Reasoning in Language Models" keynote speech
-
2026
大規模言語モデルに推論を教えるための人工論理推論コーパスを用いたアプローチ link
言語処理学会 論文賞招待セッション
-
2026
一つの論文との出会いから始まった,大規模言語モデルに「考えること」を教える企み link
『自然言語処理』33巻2号
-
2025
数理論理学に基づく人工コーパスの構築、および強化学習によるLLMの推論能力の向上 link
情報論的学習理論ワークショップ (IBIS2025)
-
2025
大規模言語モデルに推論を教えるための人工論理推論コーパスを用いたアプローチ link
『自然言語処理』
-
2024
Enhancing Reasoning Capabilities of LLMs via Principled Synthetic Logic Corpus link
Annual Conference on Neural Information Processing Systems
-
2024
LLMに論理推論を教えられるか? - 人工コーパスを用いたアプローチ link
NLPコロキウム
-
2024
帰納的に多様な巨大論理推論コーパスによりLLMの汎用論理推論能力を向上させる link
人工知能学会全国大会論文集 第38回
-
2024
JFLD: A Japanese Benchmark for Deductive Reasoning based on Formal Logic link
Proceedings of the Joint International Conference on Computational Linguistics, Language Resources and Evaluation
-
2024
日本語論理推論ベンチマークJFLDの提案 link
言語処理学会 第30年次大会 発表論文集
-
2024
生成AIの論理的思考能力を強化するための学習データを自動生成する基本技術を開発 link
日立製作所 プレスリリース
-
2024
言語モデルの論理推論能力を大きく改善、日立が学習用コーパスの自動生成技術 link
日経ロボティクス取材記事 (2024年1月号)
-
2023
人工演繹推論コーパスによる学習は言語モデルをどのように強化するか? link
人工知能学会全国大会論文集 第37回
-
2023
Learning Deductive Reasoning from Synthetic Corpus based on Formal Logic link
International Conference on Machine Learning
-
2023
形式論理学に基づく演繹コーパスによる言語モデルに対する演繹推論能力の付与 link
言語処理学会 第29回年次大会 発表論文集
SNSポストの意図解析技術の開発、及び国際コンペティションへの参加
独自のアーキテクチャを提案し、国際的に著名なSemEvalとCoNLLに参加。複数タスクで優勝。
ソーシャルメディアの登場により、インターネット上では多様な投稿が大量に発信されています。 健全なオンライン空間を実現するためには、これらの投稿の背後に込められた「意図」を正確に分析することが重要となります。
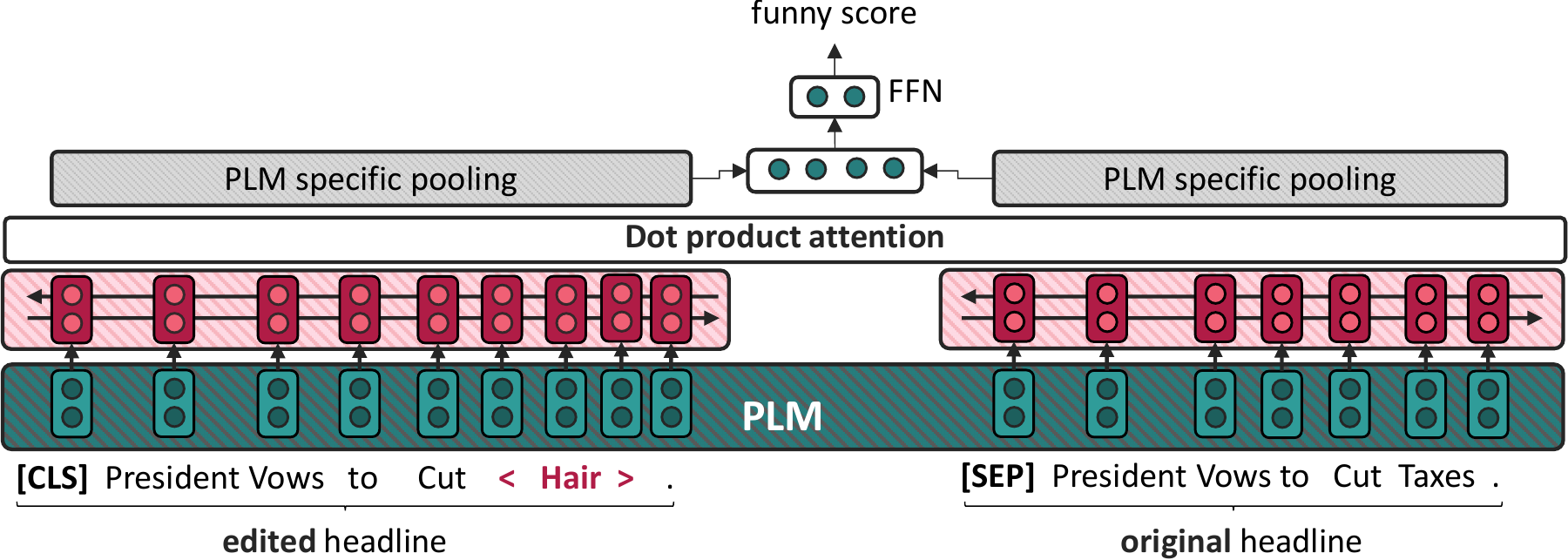
私は、意図解析に関する国際コンペティション「SemEval 2020」にて、複数のタスクに参加しました。 例えば、SNSポスト群の中からプロパガンダを検知する、インターネットミーム画像に込められた感情を推定する、「ニュースの記事タイトルを面白おかしく改変したポスト」について、そのユーモア度合いを評価する、といったタスクなどです。
私はまず、最先端の言語モデルに対して、各タスクの性質に合わせた特化アーキテクチャを追加しました。 例えば前述のユーモア評価タスクの場合は、改変前後の記事タイトルを入力し、新しく追加したcross-attention層によって、両者の差分や関係性を比較・分析させました。 さらに、単一の言語モデルでは捉えきれない特徴を補完するために、複数の言語モデルを独自のレシピに基づいてアンサンブルしました。 その結果、高精度を達成し、複数のタスクにおいて1位を獲得しました。
また、意図を正確に捉えるためには、文中の単語や句がどのような関係を持つのかという、文の意味構造を解析することも重要です。 私は、この構造解析、すなわちパーシングを題材とする「CoNLL 2020 Shared Task」にも参加し、こちらでも1位を獲得しました。
以上の取り組みを通じて、最先端の言語モデルを実課題に適用する際には、タスクの性質を踏まえたモデル設計や学習方法の工夫が重要であることを学びました。 なかでも、複数モデルの強みを組み合わせるアンサンブル学習の有効性を強く実感し、後の研究テーマへとつながりました。
既存発表
-
2020
Hitachi at SemEval-2020 Task 3: Exploring the representation spaces of transformers for human sense word similarity link
Proceedings of the Fourteenth Workshop on Semantic Evaluation
-
2020
Hitachi at SemEval-2020 task 7: Stacking at scale with heterogeneous language models for humor recognition link
Proceedings of the Fourteenth Workshop on Semantic Evaluation
-
2020
Hitachi at SemEval-2020 task 8: Simple but effective modality ensemble for meme emotion recognition link
Proceedings of the Fourteenth Workshop on Semantic Evaluation
-
2020
Hitachi at SemEval-2020 Task 10: Emphasis Distribution Fusion on Fine-Tuned Language Models link
Proceedings of the Fourteenth Workshop on Semantic Evaluation
-
2020
Hitachi at SemEval-2020 task 11: An empirical study of pre-trained transformer family for propaganda detection link
Proceedings of the Fourteenth Workshop on Semantic Evaluation
-
2020
Hitachi at MRP 2020: Text-to-graph-notation transducer link
Proceedings of the CoNLL Shared Task: Cross-Framework Meaning Representation Parsing
-
2020
自然言語処理の国際コンペティション「CoNLL 2020 Shared Task」と「SemEval 2020」の複数部門で1位を獲得 link
日立製作所 プレスリリース
アンサンブル学習における基礎理論の提唱
根本的な謎である「アンサンブルの性能を決める要素」を解明。情報理論に基づき、アンサンブルの誤差下限を3要素に分解。
アンサンブル学習では、複数のモデルの予測を組み合わせることで、より高精度な予測を達成します。 シンプルかつ強力なので、機械学習では非常に人気の高い手法です。 研究も盛んに行われてきており、様々な手法が提案されてきました。
しかしながら、アンサンブル学習には根本的な謎が残されてきています。 それは、「アンサンブルの性能を決定づける要素とは何か」という謎です。 この謎を解明することは、より良い手法を設計するために不可欠です。
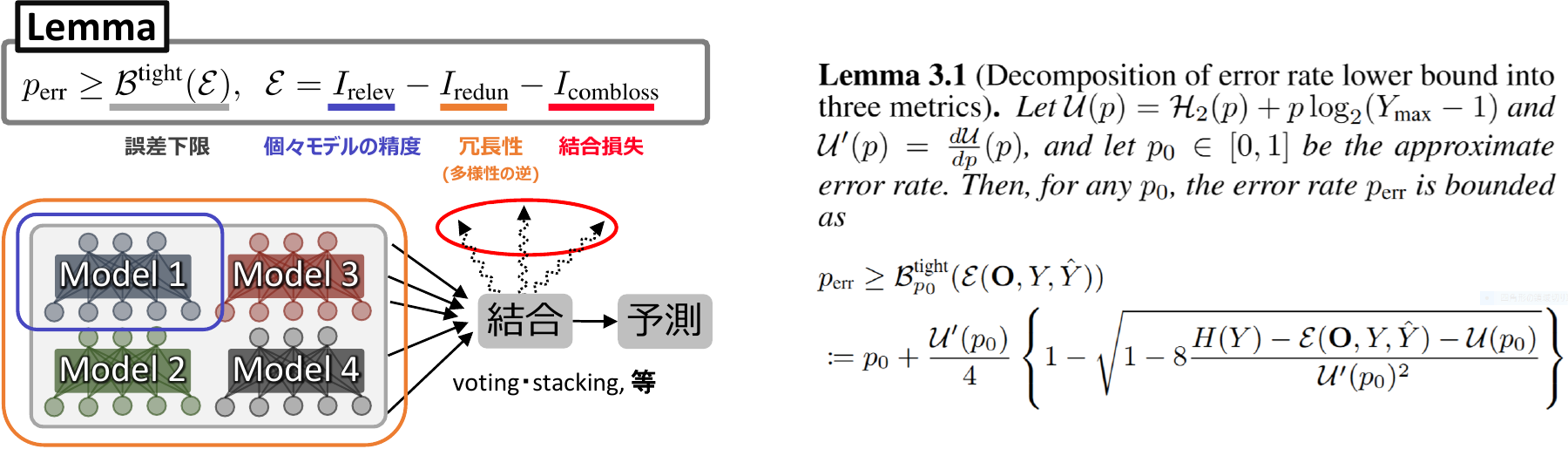
私は、この謎を解明することに成功しました。 すなわち、アンサンブルの性能は、「個々のモデルの精度」「モデル間の多様性」「モデルの予測を結合する際の情報ロス (結合損失)」という3つの要素で決まります。
個々のモデルが高精度であることはもちろん重要です。 また、モデル間に多様性があれば、あるモデルの誤りを別のモデルが補うことができます。 しかし、複数の予測を組み合わせる際に、正しい予測が他の誤った予測に埋もれてしまうこともあります。 このような場合は情報のロスが大きくなり、アンサンブルの性能は十分に発揮されません。
私は、謎の解明にあたり、情報理論の「Fanoの不等式」に着目しました。 Fanoの不等式は、雑音のある情報を復元する際の、誤り率の下限を与えるものです。 アンサンブルの文脈に置き換えると、アンサンブル手法の誤り率の下限 (性能のバロメーター)を示すことになります。 そして、私は、この下限が、上記の3つの要素に分解されることを、数学的に示しました。
私はさらに、さまざまなアンサンブル手法についてこれらの要素を計算し、どの手法がどの要素に強みを持つのかを分析しています。 このような分析は、より良いアンサンブル手法を設計する際の参考になります。
なおこの研究は、SemEval・CoNLLという意図解析の国際コンペティションで、アンサンブル手法を用いて好成績を収めた経験をきっかけに、始まったものです。
多数のLLMエージェントを用いた全世界マクロ経済シミュレーション
LLMにより人間の行動をモデル化。経済理論に基づく動学モデルを構築し、1,000体のLLMを配置。50年間の世界経済をシミュレート。
近年、AIの発展は著しく、物理学や数学をはじめとする自然科学の分野で広く活用されつつあります。 一方で、人間社会の現象を分析する社会科学においては、AIの活用はいまだ発展途上にあります。
経済学は、社会科学の中でも大きな影響力を持つ学問です。 人類社会をより豊かにするため、経済現象を解明してきました。 今までは主に、理論的なアプローチが用いられてきました。 人間が意思決定をする際に満たすであろう性質を数学的な公理として設定し、実際の人間の行動を演繹的に導出してきました(注参照)。
一方で、経済現象をより深く理解するためには、理論だけでなく、実験による検証も重要です。 ところが、人間社会そのものを実験対象とすることには、倫理的制約やコストの問題があります。 そのため、経済学はしばしば「実験が難しい学問」とされてきました。
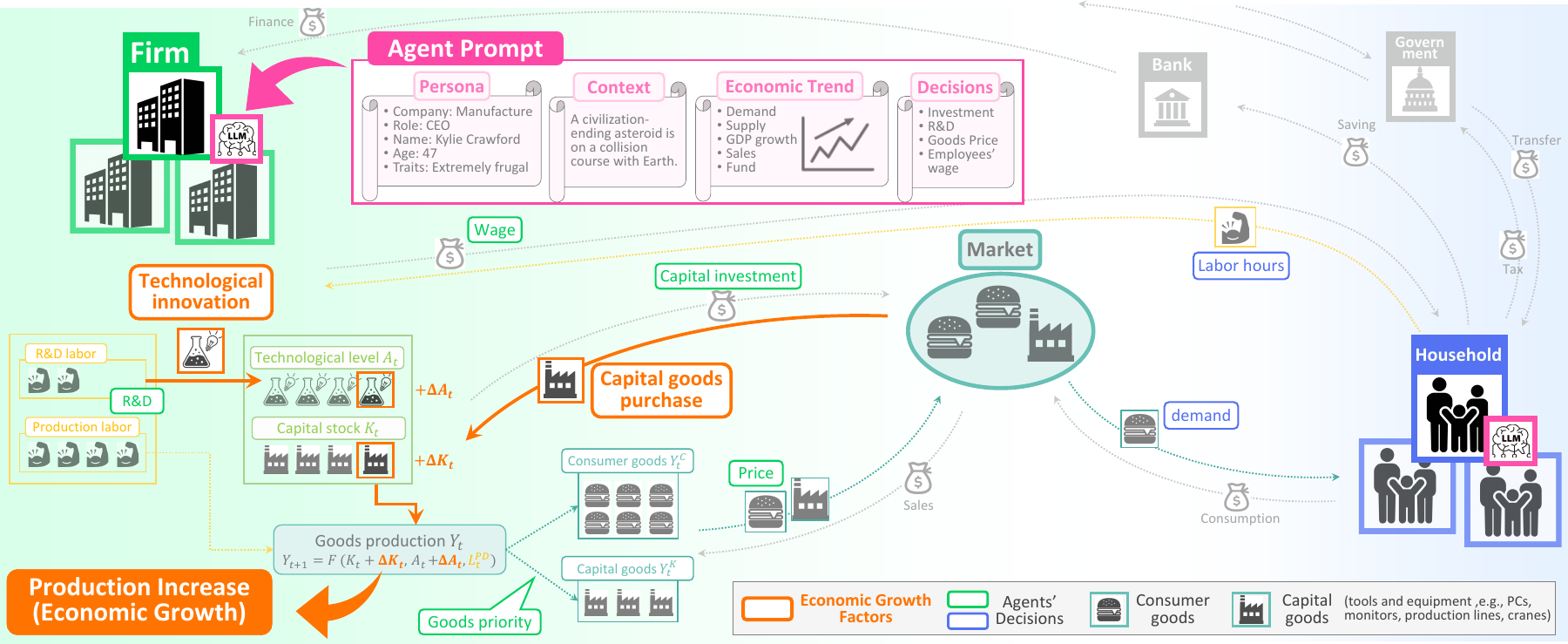
私は、この限界を乗り越えるために、経済現象を計算機上でシミュレーションすることを目指しています。 大規模言語モデル (LLM)を用いて個々の人間の行動をモデル化し、それらが相互作用することで生じる経済現象を分析します。 具体的には、消費者や企業をモデル化したLLMを合計1,000体用意して、私が構築した経済理論に基づく動学環境の中で、相互作用させました。 その結果、「経済成長」や「国際貿易」といった既知の経済現象が再現されることを確認しました。
さらに私は、「文明崩壊級の隕石の接近」というシナリオも実験しました。 その結果、人々は愛する人と最期の時間を過ごすために労働を放棄し、企業は投資や研究開発といった長期的戦略を捨て去りました。 結果として、経済全体が崩壊していく様子が観察されました。
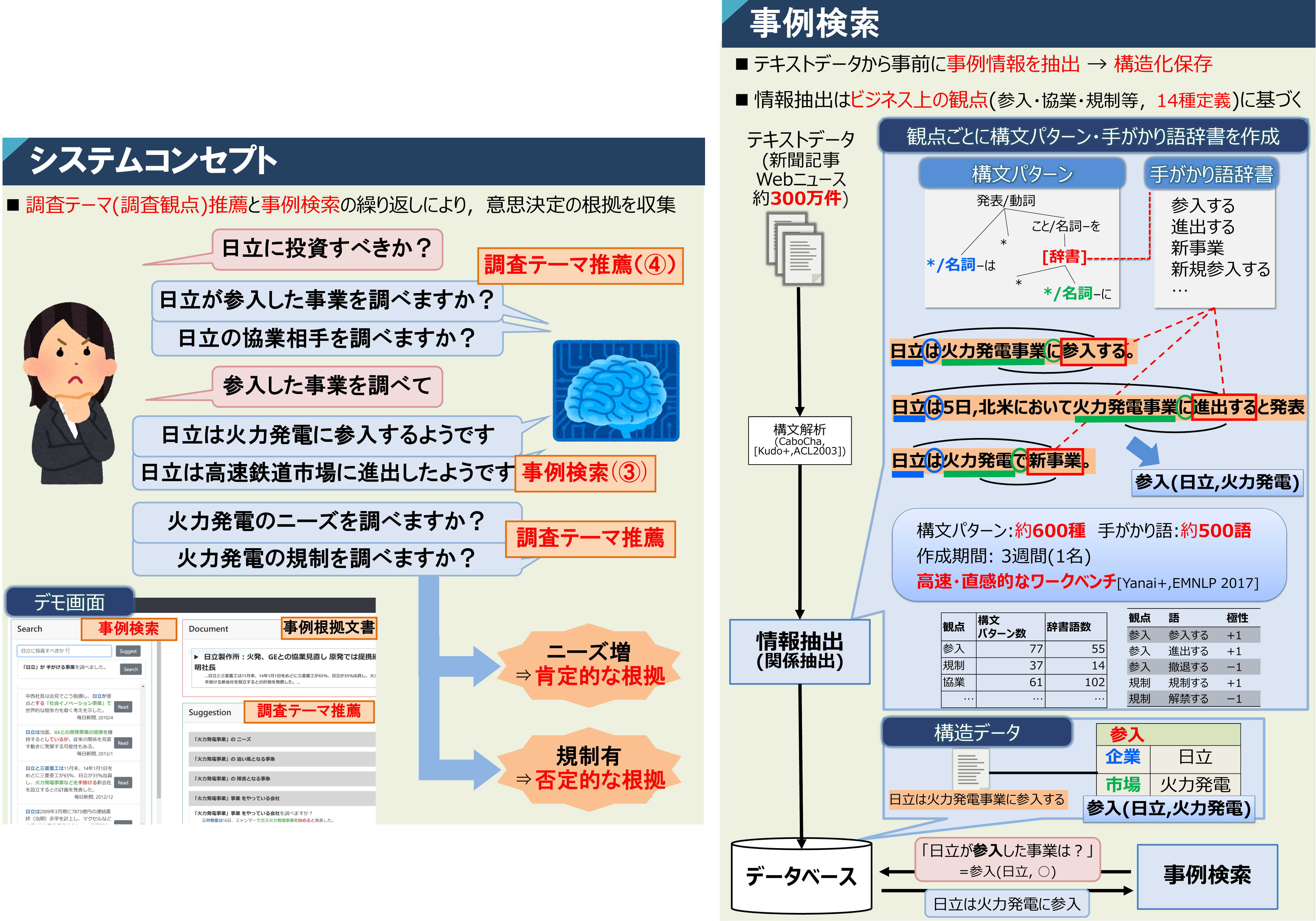
実用システム - 経営判断のための、ビジネス上の観点による情報検索システム
市場環境や他社動向といった観点に基づき、膨大なテキストデータから有用な事例を検索し、経営層の判断をサポート。
「弊社はアフリカでの火力発電事業に投資すべきか?」
的確な経営判断を行うためには、対象となる市場や技術について、多角的な観点から情報を収集し、考察を深めることが重要です。 例えば、「アフリカで火力発電のニーズはあるか」「他社はその市場に参入しているか」「現地の規制や政策は事業に追い風となるか」といった観点です。
私は、このようなビジネス特有の観点に基づいて情報を検索し考察するためのアプリケーションを開発しました。 本アプリケーションの中核技術は、テキスト中に現れる関係性を抽出する「関係抽出」技術です。 具体的には、「AはBにニーズがある」「AがBに参入する」「AがBを規制する」「AとBが協業する」といったビジネス上重要な関係性を、構文パターンや述語表現に基づいて解析します。 この技術により、新聞記事やWeb上のデータなど、膨大なテキストデータの中から、経営判断に有用な情報を効率的に検索することができます。
本アプリケーションではさらに、ユーザが入力したテーマに対して、次に調べるべき観点も推薦します。 例えば、ユーザが「X事業に参入すべきか」と考えている場合、「X事業に対するニーズ」「X事業における競合他社の動向」「X事業に関する規制」といった調査観点を提示します。 これにより、単なる情報検索にとどまらず、経営判断に必要な考察を段階的に深めていくことができます。
暗黒物質の起源の探索
天の川銀河の中心における観測データに基づき、超対称性理論が予言する新粒子が暗黒物質の候補として妥当かどうかを評価
宇宙には、光では直接見ることのできない「暗黒物質」 (ダークマター)が大量に存在すると考えられています。 しかし、その正体はいまだ明らかになっておらず、現代物理学における最大の謎の一つです。
本研究では、暗黒物質の候補として、既存の物理理論を超える「超対称性理論」から予言される「ウィーノ (Wino)」と呼ばれる粒子に注目しました。 ウィーノが暗黒物質であれば、天の川銀河の中心付近で、ウィーノ同士の対消滅により、ガンマ線 (高エネルギーの電磁波)を放出する可能性があります。
一方で、このガンマ線の強さや分布は、銀河中心付近における暗黒物質の空間分布に大きく依存します。
そこで本研究では、さまざまな天体観測データを用いて、この空間分布を推定しました。 さらに、この空間分布とガンマ線観測データを組み合わせることで、ウィーノが暗黒物質候補として妥当かどうかを検証しました。
その結果、現在得られている観測データの範囲では、ウィーノは暗黒物質候補として妥当であることが分かりました。

既存発表
-
2014
Constraints on Wino Dark Matter from the Milky Way Galaxy
修士論文, 東京大学大学院 理学系研究科 物理学専攻
Automatic generation of logical-reasoning corpora for improving LLM reasoning
We proposed design principles for logical-reasoning examples grounded in symbolic logic, developed an automatic generation algorithm, and substantially improved the reasoning capabilities of LLMs through large-scale training.
The ability to follow logic step by step is one of the foundations of human intellectual activity. Large language models can generate fluent text from vast amounts of knowledge, but can they reason in a logically correct way?
We study how to teach logical reasoning to LLMs.
As a starting point, we organized the characteristics of logical reasoning by drawing on symbolic logic and related fields.
In logical reasoning, new facts are derived by applying inference rules, for example deriving B from the facts A and if A then B.
There are many such rules, but many can be derived from a small set of more fundamental ones.
Based on this view, we designed logical-reasoning problems for LLMs.
Starting from given facts, the model applies fundamental inference rules one step at a time until it reaches the final answer.
By instantiating A and B with many different facts, the model can also learn the generality of the rules themselves.
We then developed an automatic generation algorithm that can produce large numbers of such problems. It first constructs the skeleton of a problem by stacking inference rules over multiple steps and then generates concrete facts using vocabularies and natural-language templates.
Training LLMs on the generated problems led to substantial gains on logical-reasoning tasks. We also observed improvements on broader reasoning tasks such as mathematics, science, and coding. We believe this is because logical reasoning forms a foundation for many kinds of reasoning.
This project has continued since around 2022. In addition to training data, we are also developing benchmarks for evaluating the reasoning capabilities of LLMs. Our goal is not merely plausible answers, but genuinely correct reasoning.
Related Publications
-
2026
Can We Teach Logical Reasoning to LLMs? – An Approach Using Synthetic Corpora link
AAAI Bridge Program "Logical and Symbolic Reasoning in Language Models" keynote speech
-
2024
Enhancing Reasoning Capabilities of LLMs via Principled Synthetic Logic Corpus link
Annual Conference on Neural Information Processing Systems
-
2024
JFLD: A Japanese Benchmark for Deductive Reasoning based on Formal Logic link
Proceedings of the Joint International Conference on Computational Linguistics, Language Resources and Evaluation
-
2023
Learning Deductive Reasoning from Synthetic Corpus based on Formal Logic link
International Conference on Machine Learning
Participation in international NLP competitions
We participated in SemEval and CoNLL, two leading international NLP competitions, and won first place in multiple tasks on intent analysis and semantic parsing.
With the rise of social media, the internet is now filled with posts written with many different intents. Technologies for analyzing those intents are increasingly important for building healthy and safe online spaces.
We participated in multiple tasks at the international competition SemEval 2020, including tasks on intent analysis. One example asked a language model to assess how funny an edited news headline was.
Our approach started by extending state-of-the-art language models with task-specific architectures. For the humor task, we fed both the original and edited sentences into the model and used an added cross-attention layer to compare them. We then built ensembles of multiple models according to our own recipe and achieved high accuracy. As a result, we won first place in multiple tasks.
Accurate intent analysis also requires understanding the semantic structure of sentences. We therefore participated in the CoNLL 2020 Shared Task, which focused on semantic parsing, and won first place there as well.
These experiences later deepened our interest in ensemble learning and led to one of our subsequent research themes.
Related Publications
-
2020
Hitachi at SemEval-2020 Task 3: Exploring the representation spaces of transformers for human sense word similarity link
Proceedings of the Fourteenth Workshop on Semantic Evaluation
-
2020
Hitachi at SemEval-2020 task 7: Stacking at scale with heterogeneous language models for humor recognition link
Proceedings of the Fourteenth Workshop on Semantic Evaluation
-
2020
Hitachi at SemEval-2020 task 8: Simple but effective modality ensemble for meme emotion recognition link
Proceedings of the Fourteenth Workshop on Semantic Evaluation
-
2020
Hitachi at SemEval-2020 Task 10: Emphasis Distribution Fusion on Fine-Tuned Language Models link
Proceedings of the Fourteenth Workshop on Semantic Evaluation
-
2020
Hitachi at SemEval-2020 task 11: An empirical study of pre-trained transformer family for propaganda detection link
Proceedings of the Fourteenth Workshop on Semantic Evaluation
-
2020
Hitachi at MRP 2020: Text-to-graph-notation transducer link
Proceedings of the CoNLL Shared Task: Cross-Framework Meaning Representation Parsing
A fundamental theory of ensemble learning
Using information theory, we decomposed a lower bound on ensemble error into three components and thereby identified the fundamental factors that determine ensemble performance.
Ensemble learning combines the predictions of multiple models to achieve higher accuracy. Because it is simple and powerful, it has become one of the most popular techniques in machine learning, and many methods have been proposed over the years.
Even so, ensemble learning has long contained a fundamental question: what determines the performance of an ensemble? Answering this question is essential for designing better methods.
We approached this question through theoretical analysis. We showed that ensemble performance is determined by three elements: the accuracy of each individual model, the diversity among models, and the information loss that occurs when combining their predictions (fusion loss).
High individual accuracy is of course important. Diversity among models is also valuable because one model can correct the mistakes of another. Yet when multiple predictions are combined, correct signals can be buried under incorrect ones. In such cases, information loss becomes large, and the full potential of the ensemble cannot be realized.
To analyze this problem, we focused on Fano’s inequality from information theory. Fano’s inequality provides a lower bound on the error rate when reconstructing information from noisy observations. In the ensemble setting, it can be interpreted as a lower bound on ensemble error and thus as a barometer of ensemble performance. We proved mathematically that this lower bound can be decomposed into the three factors above.
We are now computing these factors for a range of ensemble methods to analyze which methods improve which components.
This project was motivated by our experience of achieving strong results with ensemble methods in international NLP competitions such as SemEval and CoNLL.

Related Publications
-
2022
Rethinking Fano's Inequality in Ensemble Learning link
International Conference on Machine Learning
Large-scale macroeconomic simulation with LLM agents
We modeled human behavior with 100 LLM agents and simulated 25 years within a dynamic environment grounded in economic theory.
In recent years, AI has advanced rapidly and has been widely adopted in the natural sciences, including physics and mathematics. In the social sciences, however, its use is still at an early stage.
Economics is one of the most influential fields in the social sciences. It seeks to explain economic phenomena in order to make human society more prosperous. Traditionally, it has relied mainly on theoretical approaches: researchers introduce mathematical assumptions about human behavior and then deduce their consequences.
To understand economic phenomena more deeply, experiments are also important. Yet experimenting on real human society faces ethical constraints and high costs. For this reason, economics has often been regarded as a field where experimentation is difficult.
We aim to overcome this limitation by simulating economic phenomena on computers. Using large language models, we model the behavior of individual people and firms and analyze the economic phenomena that emerge from their interactions. Specifically, we modeled consumers and firms with 100 LLM agents and let them interact within a dynamic environment grounded in economic theory. We observed well-known economic phenomena such as economic growth and international trade emerging from the simulation.
We also tested a scenario in which a civilization-ending asteroid approaches Earth. In that setting, people abandoned work to spend their final days with loved ones, while firms gave up long-term strategies such as investment and R&D. As a result, we observed the collapse of the economy as a whole.
A decision-support application for collecting and organizing information from business-relevant perspectives
“Should our company invest in thermal power generation projects in Africa?” Sound business decisions require collecting and organizing information from perspectives that directly matter to the decision itself. Examples include questions such as “Is there demand for thermal power in Africa?” and “Have competitors already entered that market?”
We developed a decision-support application that helps users collect and organize information along such business-relevant perspectives. The core technology of the system is relation extraction, which identifies important relations expressed in text. Specifically, it analyzes relations such as “A has demand for B” or “A enters B” by using syntactic analysis. By applying this technology to large amounts of text data, the system makes it possible to gather and organize information from business-relevant perspectives and use it for decision making.
Exploring the nature of dark matter through the supersymmetric wino
The universe is thought to contain a large amount of dark matter, which cannot be observed directly through light. Its nature remains unknown, making it one of the biggest mysteries in modern physics.
In this work, we focused on the wino, a particle predicted by supersymmetry, as a candidate for dark matter. If the wino constitutes dark matter, pairs of winos near the center of the Milky Way may annihilate and emit gamma rays, which are high-energy electromagnetic radiation.
The strength and spatial distribution of those gamma rays depend strongly on how dark matter itself is distributed near the Galactic center.
We therefore estimated that distribution using a range of astrophysical observations. By combining the inferred distribution with gamma-ray observations, we examined whether the wino is a plausible dark-matter candidate.
We found that, within the range allowed by currently available observations, the wino remains a viable dark-matter candidate.